
Today DigitalOcean lost our entire server
This morning I got a mail from the support department of DigitalOcean, which hosts most sites for my company Spatie. (If you're not familiar with DO-speak, "droplet" is just a synonym for "server")
... I'm reaching out regarding your droplet. Earlier today, our Cloud Operations team was alerted to some performance issues affecting the physical server that hosts your droplet and immediately began investigating. Unfortunately, despite their recovery efforts and a filesystem check of the underlying disks, the damage was serious enough that this droplet was lost and not able to be restored.Obviously, this not a mail you ever want to get. Luckily, we made the decision at Spatie to host every site on it's own droplet, so only one site was affected.While our hypervisors are all fully redundant with RAID arrays, we do not additionally backup customer data (unless the user has enabled backups for the droplet, or taken snapshots of their own) for several reasons. One of the main reasons is data privacy; for this reason, it's expected that each customer will maintain the backup solution that works for their needs and specific situation.
If you did not have a backup or snapshot of the droplet, I'm sorry to let you know that we are not able to recover your data. The droplet's ID and IP address have been saved, so you can rebuild the droplet if you'd like to keep that same IP address (avoiding any DNS changes), or simply destroy the droplet and create a new one.
...
We apologize for this situation; it's obviously a difficult place to be in, and it's not one that we take lightly, or one without having first tried any recovery methods available to us, before having to give you this bad news. We have gone ahead and granted you credit covering three months of this droplet's run rate. We understand this doesn't bring your data back, but we hope it helps as you move forward.
When visiting that website it was indeed down. Against my better judgment I tried ssh-ing into the droplet, which of course also failed. So there you have it: one day the droplet is just running fine, the next day it's gone. All data lost. Poof!
A few minutes after the mail above I received another message from DigitalOcean.
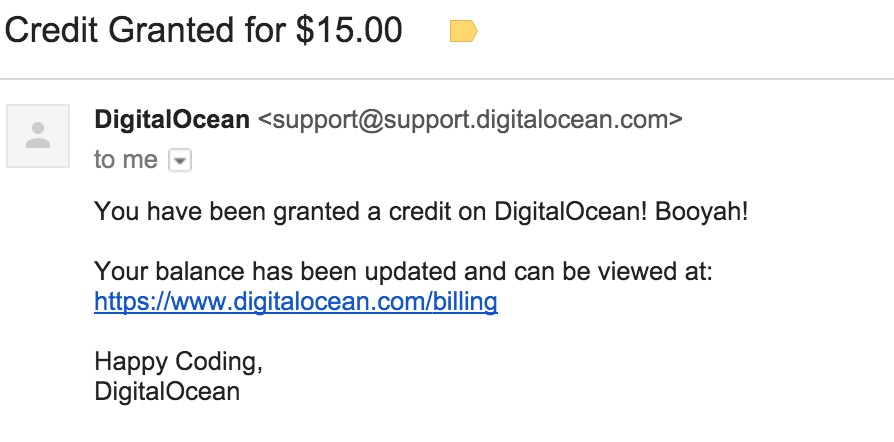
Booyah, indeed. Fifteen dollars is peanuts when you take into account that an entire server has just vanished.
DigitalOcean has a paid backup service that takes weekly snapshots of all droplets. All our droplets are using that service. Now was the time to test it out. After issuing the command restoring the snapshot took about 10 minutes. When the job was finished the server was running again. It had the same IP address as before the crash and Forge (which we use to provision/manage droplets) could establish a connection again. Unfortunately the snapshot was 7 days old so all data from the past week was lost. Our client would not have been happy to hear this.
We're fairly paranoid when it comes to backups and never wanted to put all our eggs in one basket. In addition to the weekly snapshots taken by DO's backup service, all droplets are copied daily by BackupPC to storage at Amazon. I copied over the files and database dump from that backup to the restored droplet. The result was that, in less than an hour, the site of our client was up again without data loss. Crisis averted.
In the afternoon I got a full explanation from DO why the droplet crashed:
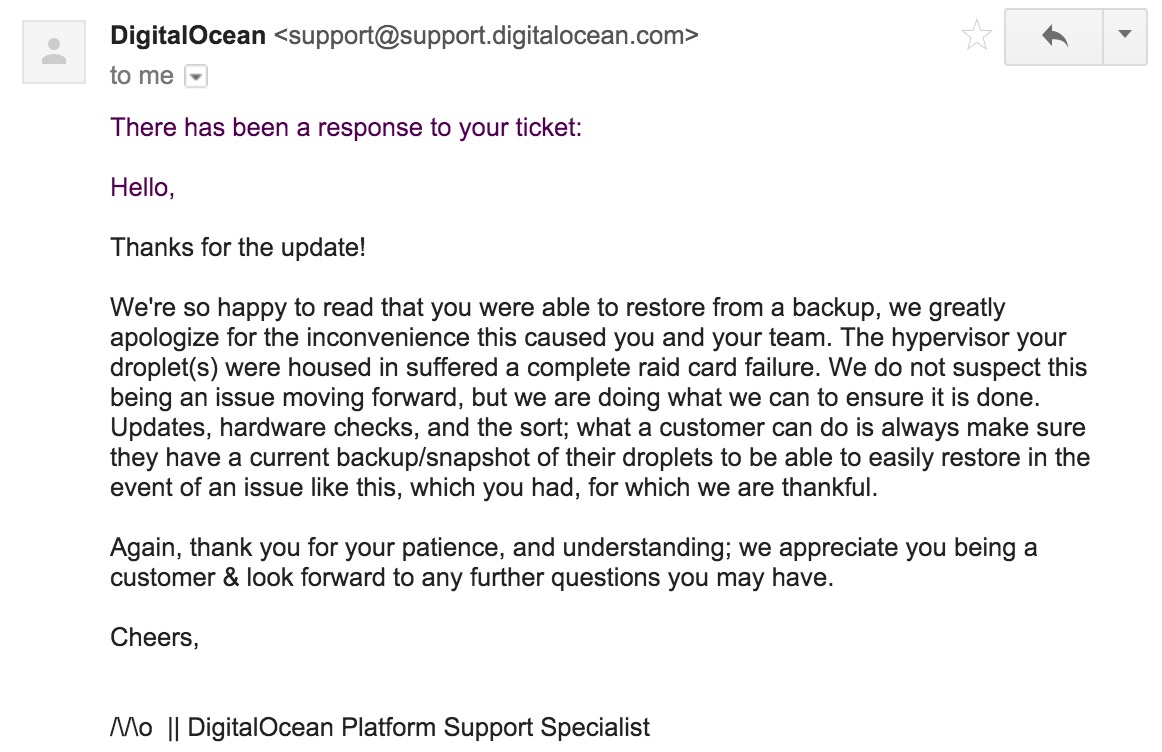
Think about this for a minute: what are you going to do when one of your servers would disappear right now? I hope you take away from this story that you should always backup your servers. A hardware failure can happen at any given moment. Do not solely rely on backups from your own provider. Take your own backups as well. Use tools like BackupPC, Bacula, or a service like SnapShooter.
If you're into Laravel you can also use Spatie's backup package which can dump your database and copy it together all your files to multiple destinations (S3, SFTP, Dropbox, ...).
What are your thoughts on "Today DigitalOcean lost our entire server"?